ChatGPT 5.5 vs Claude Opus 4.7: Which One Is Actually Better?
My honest take

TL;DR: GPT-5.5 (released April 23, 2026) and Claude Opus 4.7 (released April 16, 2026) landed seven days apart. They are not competing on the same axis.
Opus 4.7 wins repository-level coding, vision, and costs 17% less on output tokens. GPT-5.5 wins autonomous agent work, long-context retrieval, and knowledge tasks across 44 occupations.
Key takeaways
→ Opus 4.7 leads SWE-bench Pro (64.3% vs 58.6%) and SWE-bench Verified (87.6% vs GPT-5.5’s comparable range). GPT-5.5 leads Terminal-Bench 2.0 (82.7% vs 69.4%) and GDPval (84.9%).
→ GPT-5.5 uses roughly 40% fewer output tokens per Codex task. Opus 4.7 is priced cheaper per token ($25 vs $30 output). End-to-end cost depends on your workflow.
→ Both ship with 1M token context windows. GPT-5.5 holds up significantly better on long-context retrieval past 256K.
→ Opus 4.7 has real vision advantages at 3.75 megapixel image input. GPT-5.5 is natively omnimodal (text, image, audio, video in one stack).
→ Opus 4.7 is GA on AWS Bedrock, Google Vertex AI, and Microsoft Foundry on day one. GPT-5.5 API is rolling out more cautiously.
The honest framing nobody wants to say
I have spent the last few hours running both models on real-world data, not synthetic benchmarks. Here is the thing: if you picked one model for every task, you would leave value on the table with either choice.
The lazy take is “Opus wins coding, GPT wins agents.” That is directionally right, but it misses why. These two labs are now optimizing for different product categories.
OpenAI is building toward what Brockman calls a “super app.” Anthropic is building a precision instrument for hard engineering work. The benchmarks reflect the best.
What actually changed with each release
Claude Opus 4.7
Released April 16, 2026 at anthropic.com/news/claude-opus-4–7. Pricing held at $5 input and $25 output per million tokens. Same as Opus 4.6.
The headline for me is self-verification. Opus 4.7 catches its own logical faults during planning and resists what Hex calls “dissonant-data traps.” On a 93-task internal coding benchmark, Anthropic reported a 13% resolution lift over Opus 4.6, including four tasks that Opus 4.6 and Sonnet 4.6 could not solve.
Vision jumped from 1.15 megapixels to 3.75 megapixels of usable input. One early-access partner (XBOW) reported visual acuity going from 54.5% to 98.5% on their penetration testing benchmark. That is not a rounding error.
GPT-5.5
Released April 23, 2026, at openai.com/index/introducing-gpt-5–5. Codenamed “Spud.” API pricing announced at $5 input and $30 output per million tokens. API access is still rolling out at the time of writing.
OpenAI’s bet is token efficiency plus autonomy. GPT-5.5 matches GPT-5.4 per-token latency in production while using about 40% fewer output tokens on the same Codex task. It hits 82.7% on Terminal-Bench 2.0 and 98.0% on Tau2-bench Telecom for customer service workflows.
The Microsoft and Apple distribution deals announced with the launch matter more than the benchmarks for enterprise adoption. 5.5 ships into Azure AI and Copilot simultaneously, and it will power the next generation of on-device Siri.
Comparison between ChatGPT 5.5 vs Claude Opus 4
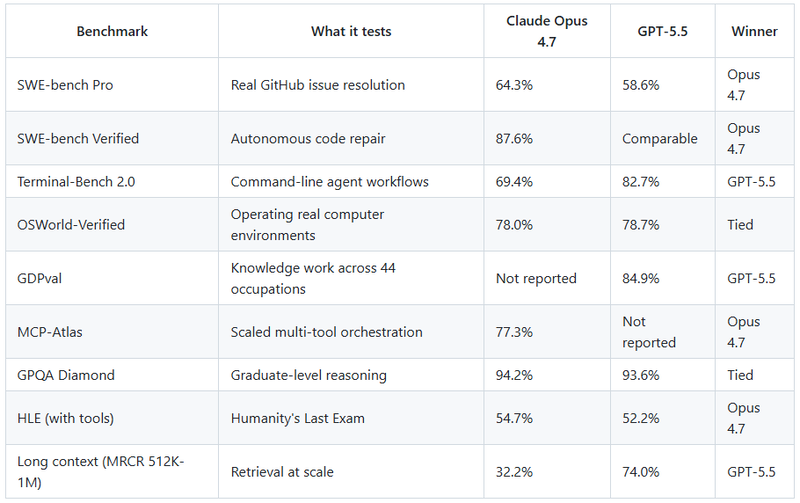
Sources: Anthropic, OpenAI system card, LLM Stats.
The long-context gap is the least reported here. At 512K to 1M tokens, GPT-5.5 retrieves more than twice as reliably as Opus 4.7. If you are feeding entire codebases or a year of financial filings into a single session, this matters more than a two-point SWE-bench difference.
Pricing and cost reality
Per-token pricing only tells part of the story because the two models consume tokens differently.
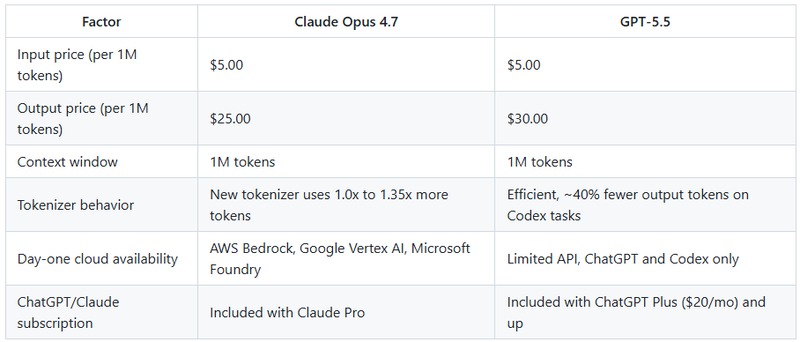
Here is the trap. Opus 4.7’s output is 17% cheaper per token, but the new tokenizer can cost you up to 35% more tokens per input. GPT-5.5 charges more per output token but writes fewer tokens in Codex-style work. Do the math on your actual workload before assuming one is cheaper.
Connect with me on LinkedIn.
My decision framework
I am not going to dress this up. Here is how I pick.
Pick Opus 4.7 if your work is large pull-request refactors, MCP-heavy pipelines, dense screenshot analysis, or anything where the model needs to admit it does not know something instead of hallucinating a plausible answer. The instruction-following is more literal, and the vision is genuinely ahead.
Pick GPT-5.5 if your work is an autonomous agent that runs with tool calling, long-context retrieval past 256K tokens, terminal-based workflows, or anything where “complete the whole task without stopping early” is the metric that matters. Also, pick it if you are already in the Microsoft stack.
Pick both if you are building a product. Route coding and vision to Opus 4.7, route agentic loops and long-context retrieval to GPT-5.5. The cost difference is not large enough to justify limiting yourself.
Where I disagree with the consensus
The narrative that “GPT-5.5 is the new SOTA” is lazy. On the nine benchmarks, both labs report that Opus 4.7 leads six. GPT-5.5 wins on categories OpenAI chose to emphasize (agentic work, long context, knowledge tasks across occupations). Anthropic wins in the categories they emphasize (code quality, self-verification, vision).
Neither is “better.” They are optimized for different bets about where AI product value lives in 2026.
FAQs
Q: Which model is better for coding agents in production?
Opus 4.7 for codebase-level work and clean PRs. GPT-5.5 for autonomous terminal agents that need to plan, execute, and recover from errors without supervision.
Q: Does GPT-5.5 really have a 10-million-token context window?
OpenAI’s API spec confirms 1M tokens, same as Opus 4.7. The 10M figure was referenced in some launch coverage, but it is not what ships in the API today.
Q: Is Claude Opus 4.7 cheaper than GPT-5.5?
Per output token, yes (17% lower). In total, the task cost depends on your workflow. GPT-5.5’s token efficiency on Codex tasks can flip the math.
Q: Which model handles images better?
Opus 4.7 for dense technical images, screenshots, and diagrams at up to 3.75 megapixels. GPT-5.5 for general multimodal, including audio and video input.
Q: Should I migrate existing GPT-5.4 or Opus 4.6 prompts to the new versions?
Test first. Opus 4.7’s literal instruction-following breaks prompts tuned for 4.6’s inference behavior. GPT-5.5’s token efficiency can affect the output length, which in turn can affect downstream parsing.

Comments
No comments yet. Be the first to comment!